Selected Projects
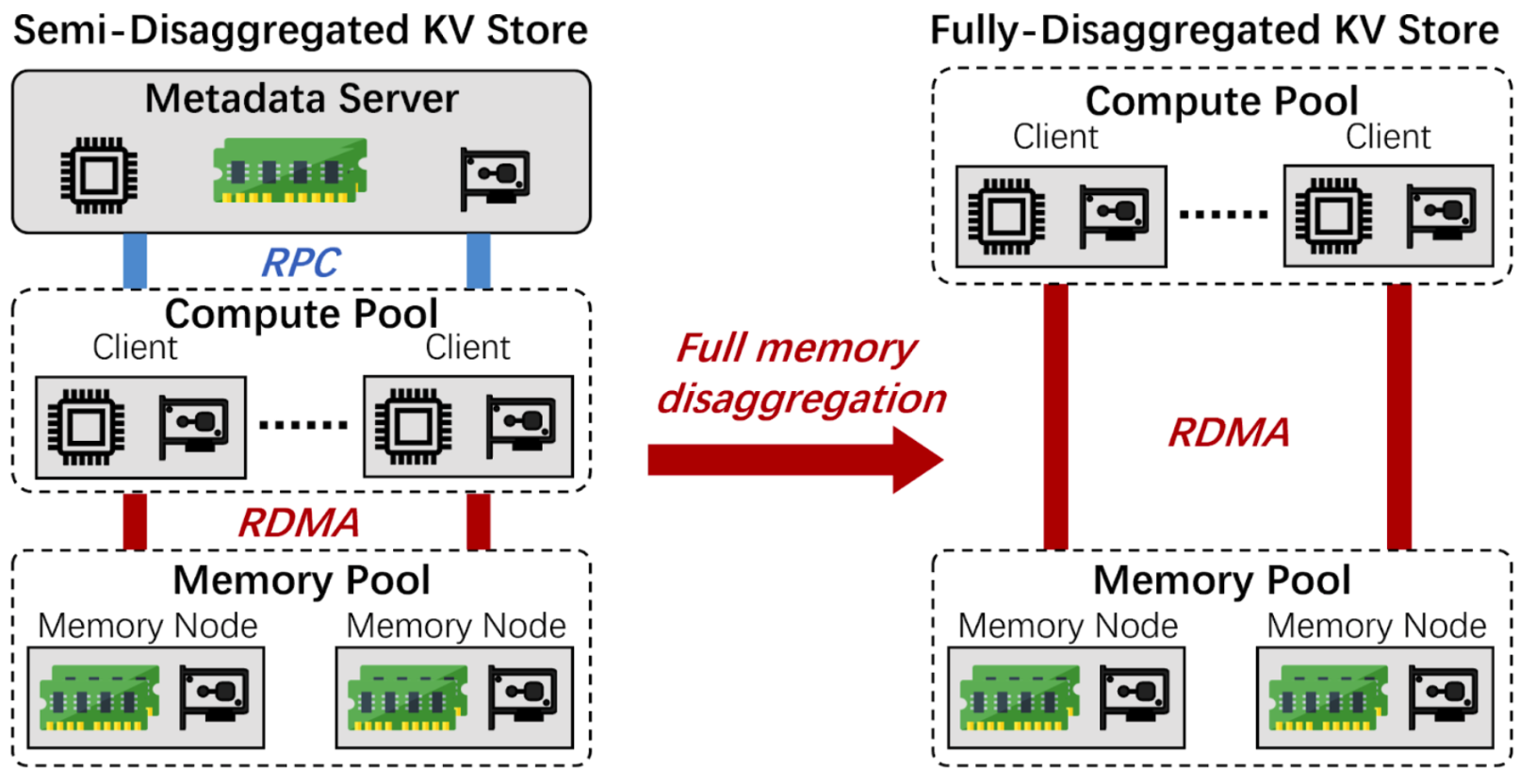
FUSEE is a fully memory-disaggregated key-value store proposed to fully
exploit the hardware benefits of the disaggregated memory architecture.
It addresses the challenges of the weak compute power on memory nodes
and the complex failure situations on the DM architecture. It uses a
client-centric index replication protocol to efficiently replicate the
hash index on multiple memory nodes to tolerate memory node failures. It
uses an embedded operation log scheme to recover the corrupted metadata
to handle client failures. Finally, it adopts a two-level memory
management scheme to efficiently allocate remote memory. Experiment
results show that compared with existing approaches, FUSEE reaches up to
4 times higher throughput under the YCSB hybrid benchmark.
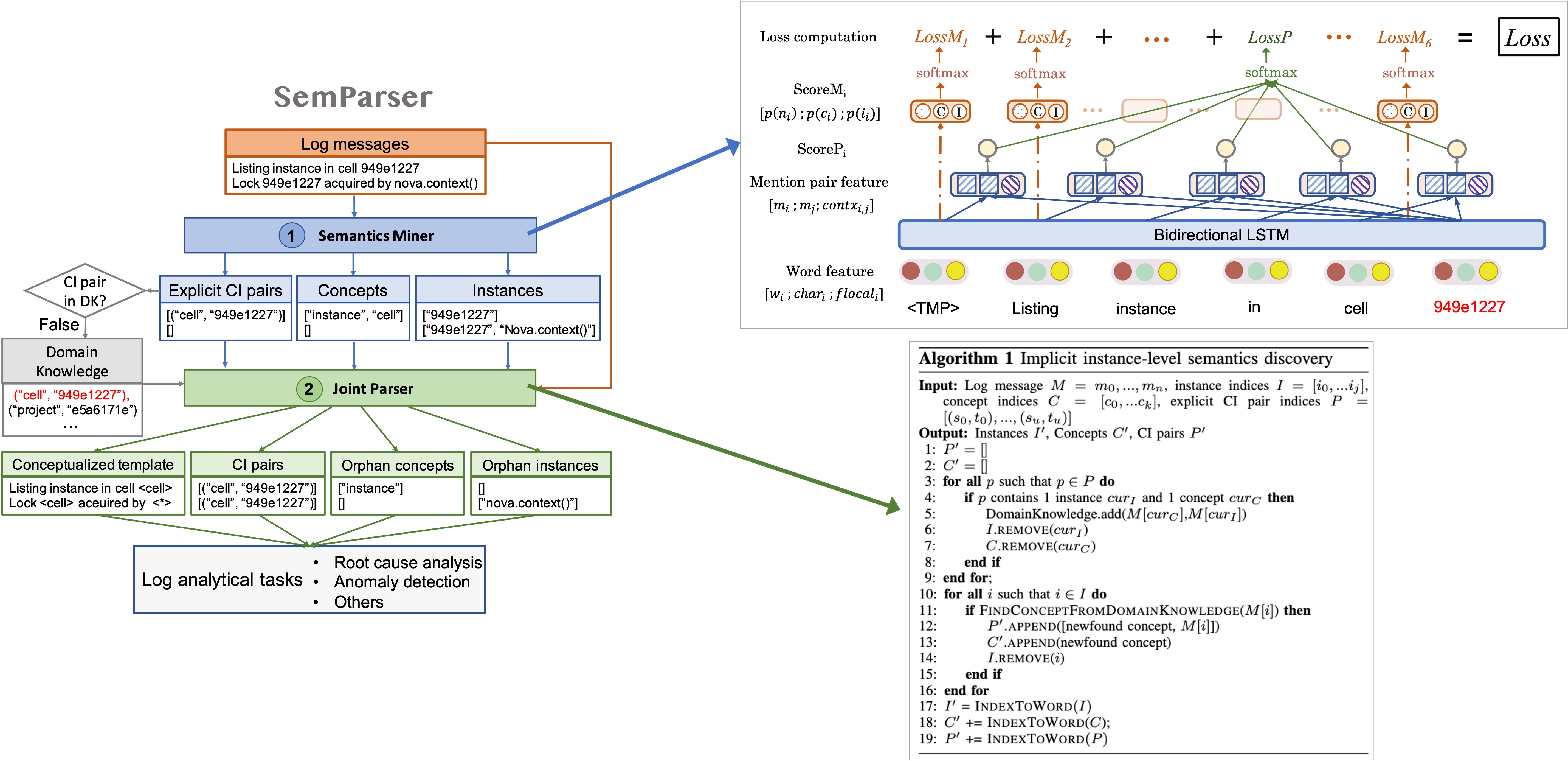
SemParser is the first semantic-based parsing approach for log analysis,
to overcome the syntax-based parser limitations on: (1) inadequate
attention to individual infor-mative tokens; (2) ignored semantics
within a message; and (3) missing semantics between messages. SemParser
unlocks these bottlenecks in two components, a semantics miner for
mining explicit semantics from messages, and a joint parser for
discovering implicit semantics across different log messages. We conduct
extensive experiments to evaluate SemParser in six
representative system logs for its powerful semantic mining ability. The
experimental results further indicate that our method outperforms
syntax-based log parsers by large margins in log analysis tasks.
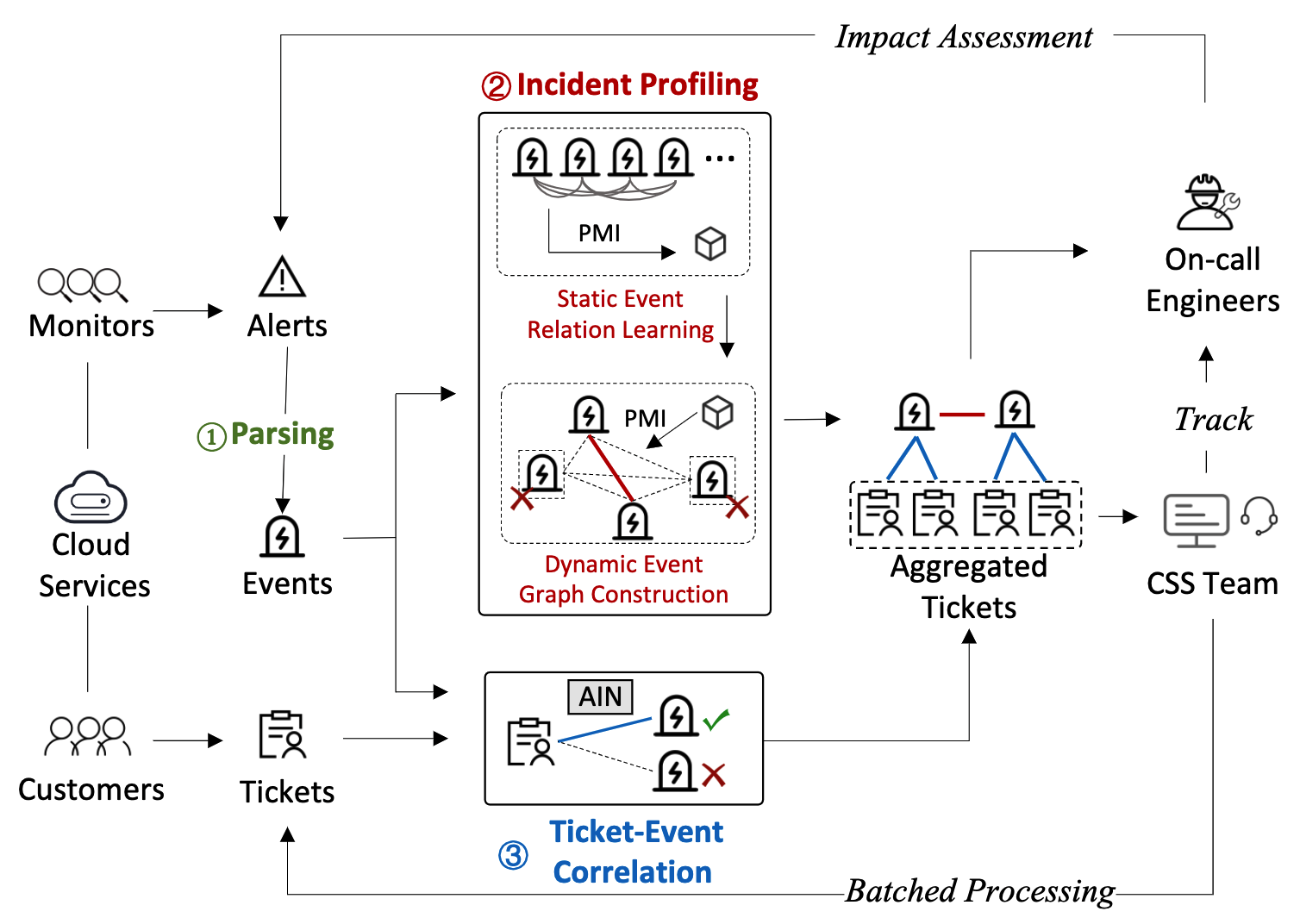
iPACK is an innovative solution to the problem of identifying duplicate
tickets in cloud systems. Previous studies have mainly relied on textual
similarity between tickets to detect duplication. However, in a cloud
system, duplicate tickets can have semantically different descriptions
due to the complex service dependency of the system. To address this
issue, we propose iPACK, an incident-aware method that aggregates
duplicate tickets by combining the failure information between the
customer side (i.e., tickets) and the cloud side (i.e., incidents). We
extensively evaluated iPACK on three datasets collected from the
production environment of a large-scale cloud platform, Azure. The
experimental results demonstrate that iPACK can accurately and
comprehensively aggregate duplicate tickets, achieving an F1 score of
0.871 to 0.935, and outperforming state-of-the-art methods by 12.4% to
31.2%.
Eadro is the first framework to integrate anomaly detection and root
cause localization into an end-to-end manner based on multi-source data
for troubleshooting large-scale microservices.
It models intra-service behaviors and inter-service dependencies from
multi-source monitoring information, including traces, logs, and KPIs,
all the while leveraging the shared knowledge of the two phases via
multi-task learning.
Experiments on two widely-used benchmark microservices demonstrate that
Eadro outperforms state-of-the-art anomaly detectors or root cause
localizers by a large margin.
This study demonstrates that logs and metrics can manifest system
anomalies collaboratively and complementarily, and neither of them only
is sufficient. Thus, we propose HADES, the first end-to-end
semi-supervised approach to effectively identify system anomalies based
on heterogeneous data. It employs a hierarchical architecture to learn a
global representation of the system status by fusing log semantics and
metric patterns via a novel cross-modal attention module. This approach
allows for prompt and accurate anomaly detection of a large-scale
software system.
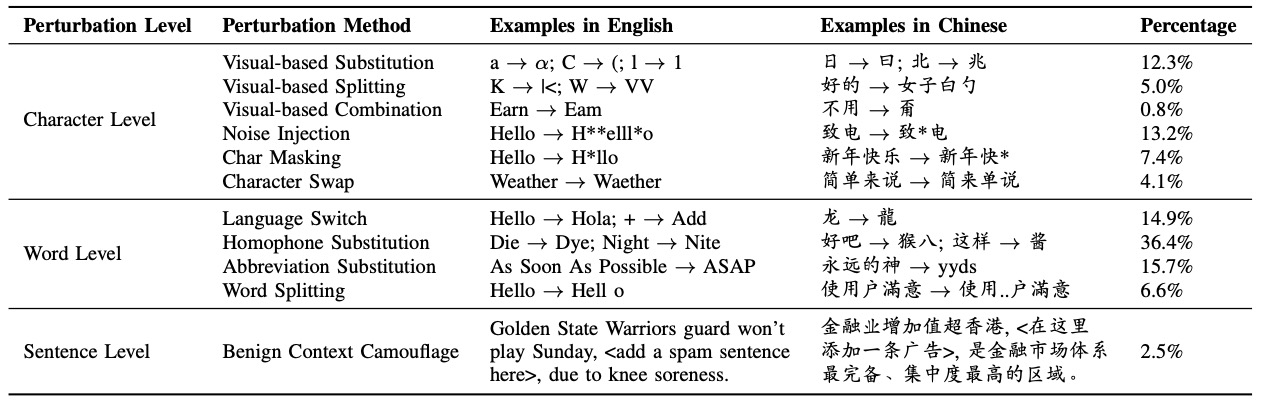
MTTM is a comprehensive testing framework for validating textual content
moderation software. It contains eleven metamorphic relations that are
mainly inspired by a pilot study. In addition, all the metamorphic
relations have been implemented for both English and Chinese. The test
cases generated by MTTM can easily evade the moderation of two SOTA
moderation algorithms and commercial content moderation software
provided by Google, Baidu, and Huawei. Also, the test cases have been
utilized to retrain the algorithms, which exhibited substantial
improvement in model robustness while maintaining identical accuracy on
the original test set.
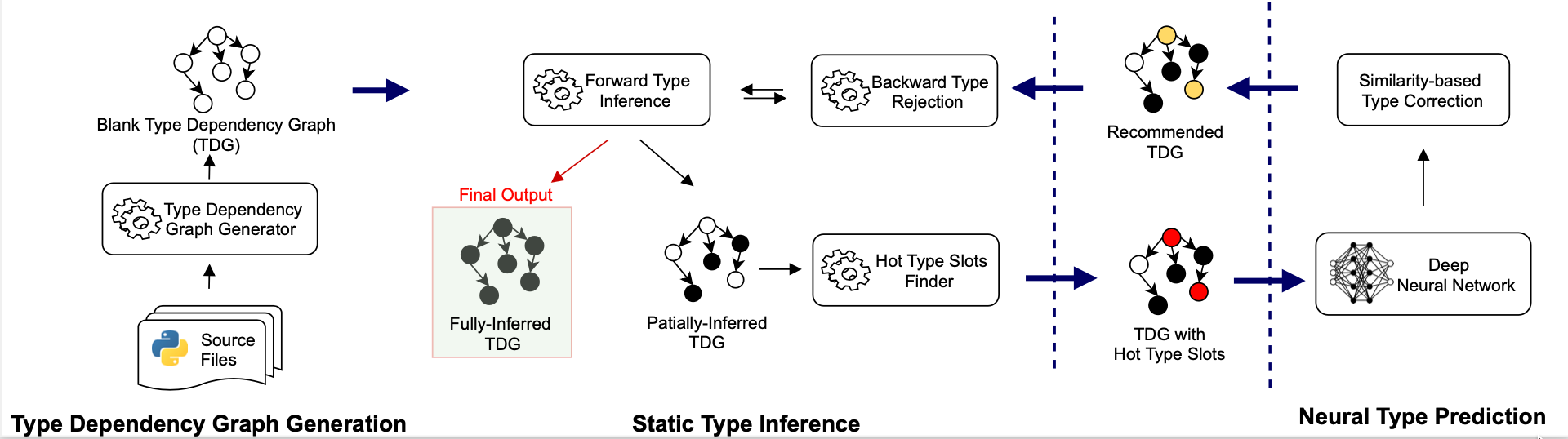
HiTyper is a hybrid type inference tool built upon Type Dependency Graph
(TDG). The general methdology of HiTyper is:
1. Static inference is accurate but suffer from coverage problem due to
dynamic features
2. Deep learning models are feature-agnostic but they can hardly
maintain the type correctness and are unable to predict unseen
user-defined types
The combination of static inference and deep learning shall complement
each other and improve the coverage while maintaining the accuracy.
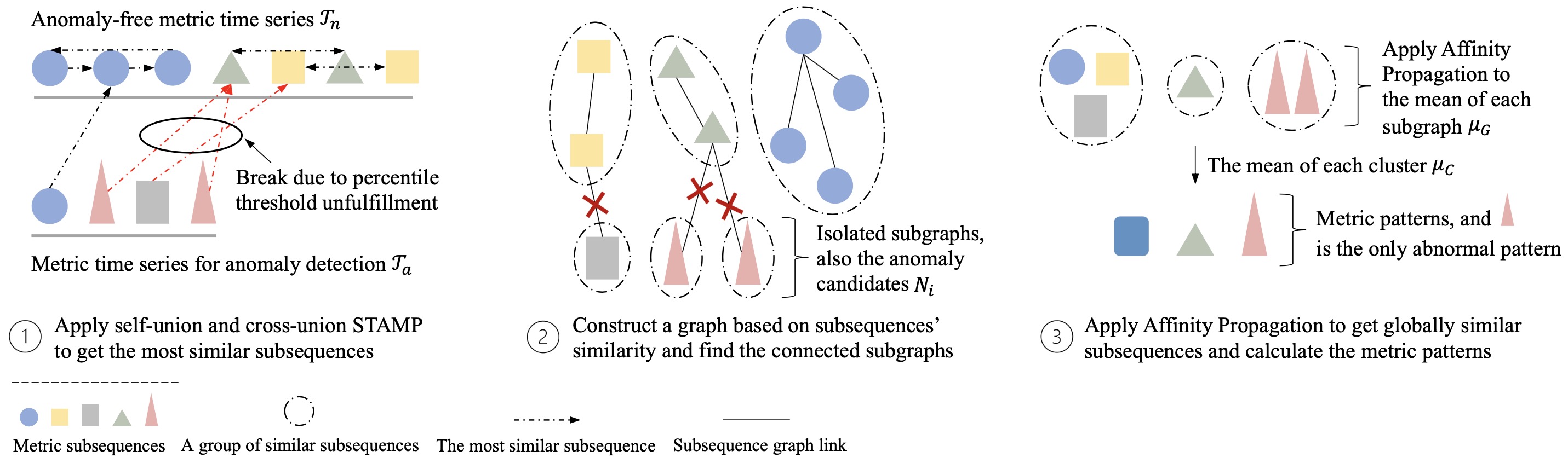
ADSketch (Anomaly Detection via Pattern Sketching) is an interpretable
and adaptive performance anomaly detection algorithm for online service
systems. Its core idea is to locate metric subsequences that
significantly deviate from those shown in the history. ADSketch achieves
interpretability by identifying groups of anomalous metric patterns,
which represent particular types of performance issues. The underlying
issues can then be immediately recognized if similar patterns emerge
again. Moreover, an adaptive learning algorithm is designed to embrace
unprecedented patterns.
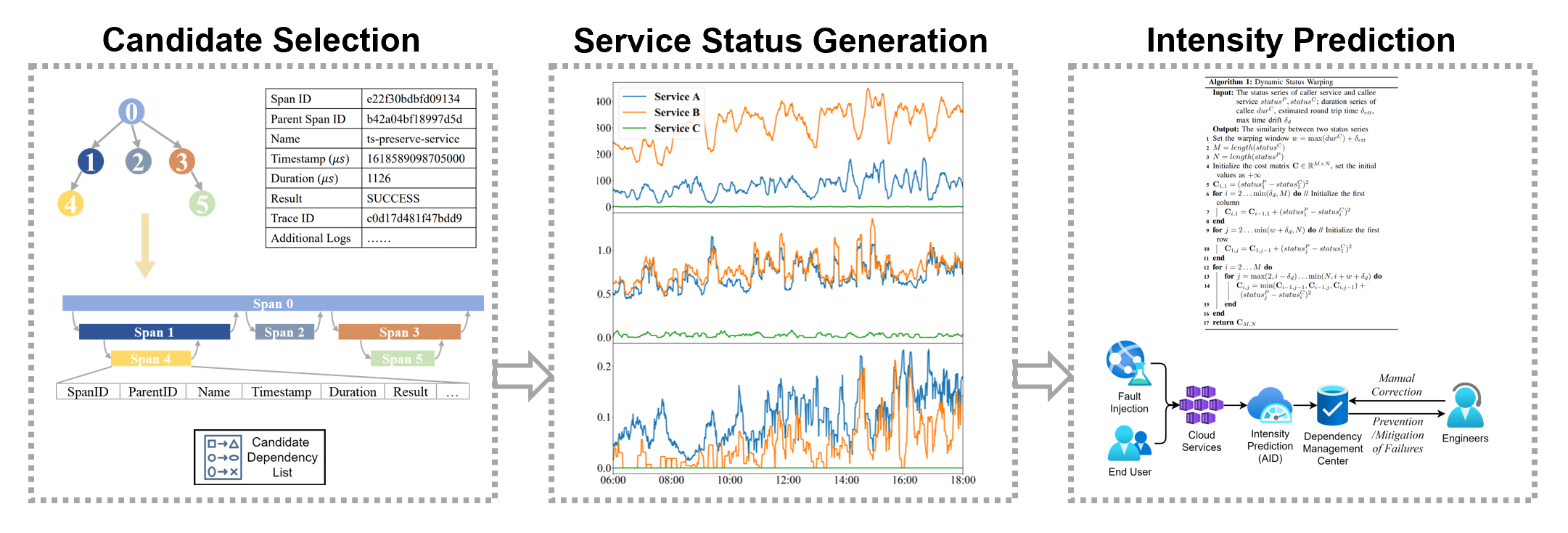
We first define the intensity of dependency between two services as how
much the status of the callee service influences the caller service.
Then we propose AID, the first approach to predict the intensity of
dependencies between cloud services. AID consists of three steps:
candidate selection, service status generation, and intensity
prediction. We further demonstrate the usefulness of our method in a
large-scale commercial cloud system. This is a joint work by CUHK and
Huawei.
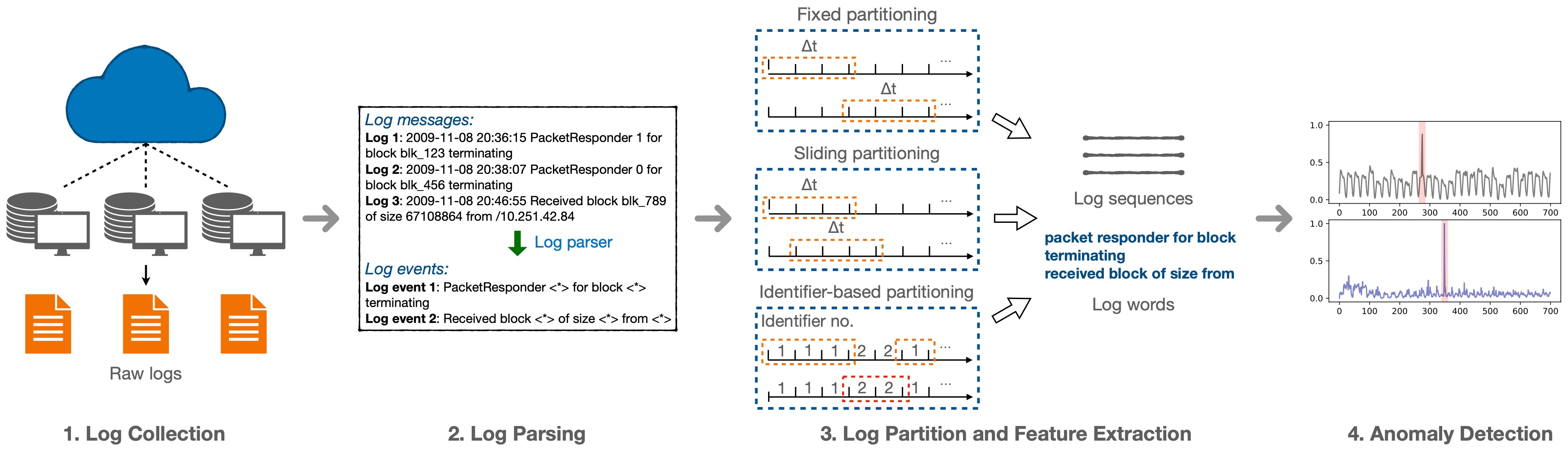
Deep-loglizer is a deep learning-based log analysis toolkit for
automated anomaly detection. It includes five popular neural networks
used by six state-of-the-art methods. These methods are evaluated with
two publicly available log datasets.
Loghub maintains a collection of system logs, which are freely
accessible for research purposes. Some of the logs are production data
released from previous studies, while some others are collected from
real systems in our lab environment. Wherever possible, the logs are NOT
sanitized, anonymized or modified in any way. All these logs amount to
over 77GB in total. We thus host only a small sample (2k lines) on
Github for each dataset.
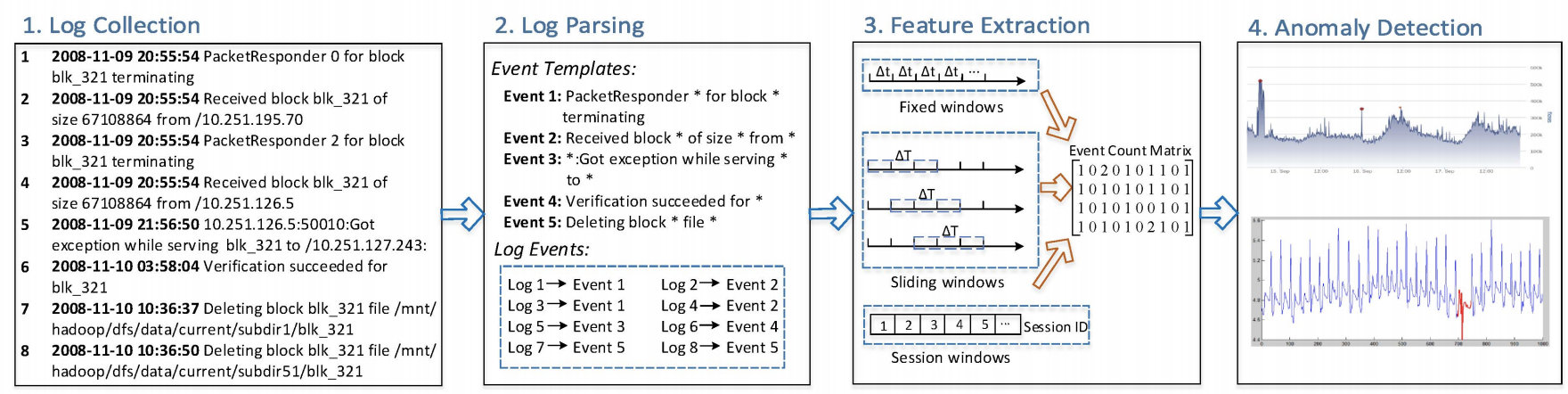
Logs are imperative in the development and maintenance process of many
software systems. They record detailed runtime information during system
operation that allows developers and support engineers to monitor their
systems and track abnormal behaviors and errors. Loglizer provides a
toolkit that implements a number of machine-learning based log analysis
techniques for automated anomaly detection.
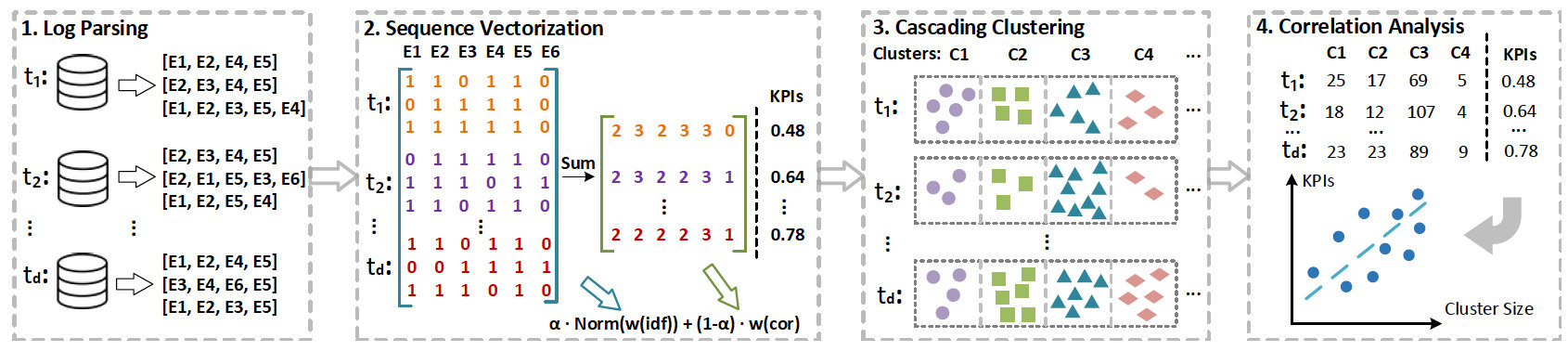
Log3C is a general framework that identifies service system problems
from system logs. It utilizes both system logs and system KPI metrics to
promptly and precisely identify impactful system problems. Log3C
consists of four steps: Log parsing, Sequence vectorization, Cascading
Clustering and Correlation analysis. This is a joint work by CUHK and
Microsoft Research.